安装CentOS 7
下载链接
最小安装版(推荐,使用此镜像不用选择软件安装,只需配置用户即可)
CentOS 安装流程及其配置
使用VM创建虚拟机,进入安装界面
选择语言
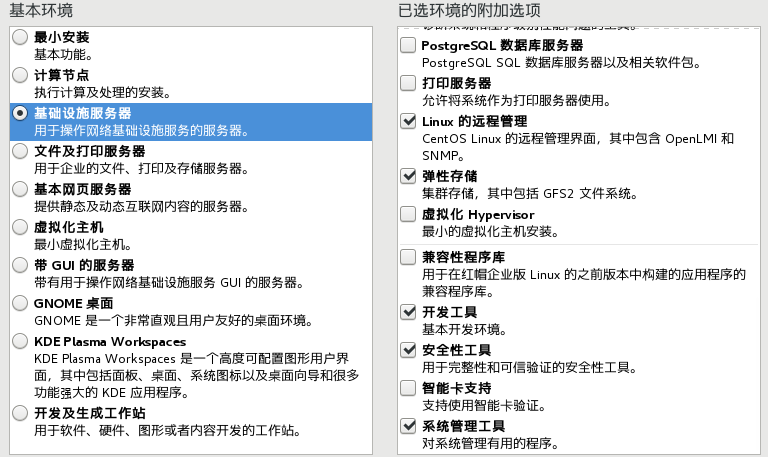
- (重要)点击软件选择
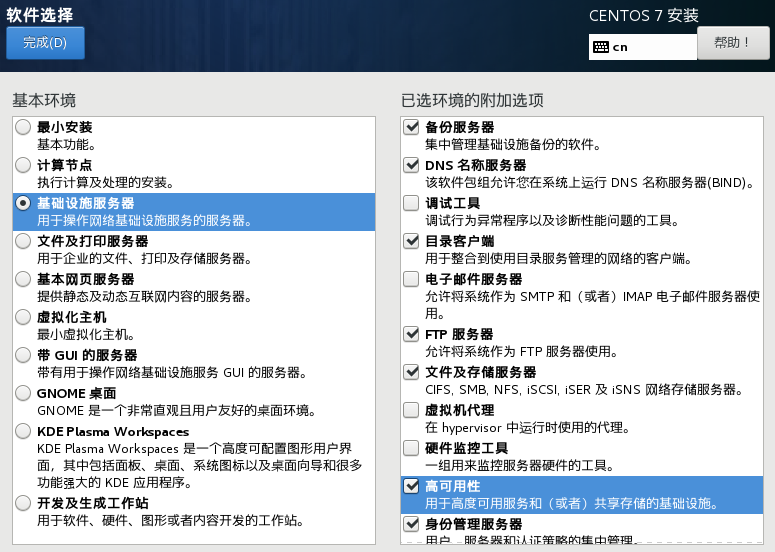
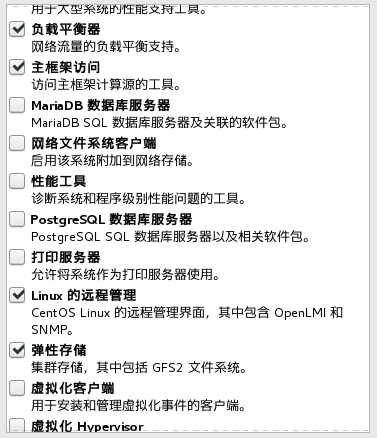
设置密码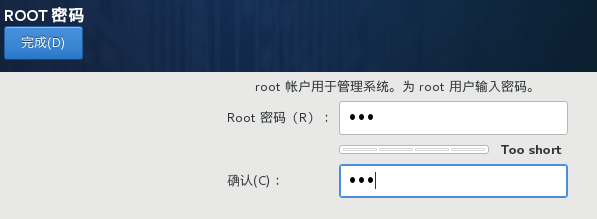
等待安装完成
修改主机名
- 使用 hostnamectl查看,修改用hostnamectl set-hostname [name]
查看&关闭防火墙
CentOS7默认使用firewall作为防火墙查看防火墙状态
- firewall -cmd –state
停止防火墙
- systemctl stop firewalld.service
禁止开机启动
- systemctl disable firewalld.service
设置IP
- vi /etc/sysconfig/network-scripts/ifcfg-ens33
- 把ONBOOT=no修改为yes
重启网络服务
- sudo service network restart
生成Hadoop账户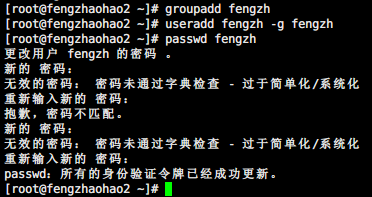
图为Slave的生成,其他也一样
配置免密码的SSH
首先,切换账户
- 使用 su - [username] 进行切换
生成密钥对
- 生成密钥 ssh-keygen -t rsa 使用rsa算法
获取本机IP地址
- ifconfig 找到ens33里面的inet,后面的就是IP地址
- 如果显示command not found,可以先ping www.baidu.com 确认虚拟机可以连接外网,然后使用yum install net-tool 安装即可使用
- 又或者使用ip addr也可获得
将需要ssh的主机加入hosts
- vi /etc/hosts
- 以 [IP地址] [主机名]的形式逐条写入
授予普通用户权限,不然无法使用scp和cat
- 用root账户操作
- chmod 640 /etc/sudoers使其可写
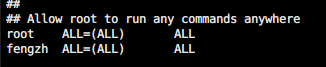 找到这个加入自己账户名称且授予权限
找到这个加入自己账户名称且授予权限- chmod 440 /etc/sudoers 复原权限
- 大功告成
分发密钥
由master机器执行以下命令
- cat id_rsa.pub >> authorized_keys 生成公钥钥信息文件
- chmod 600 authorized_keys 修改权限,使其可以使用scp传输
- scp authorized_keys slave[n]:/home/[用户名]/.ssh
slave执行
- cat id_rsa.pub >> authorized_keys
- scp authorized_keys slave[n]:/home/[用户名]/.ssh 传递到下一个slave机器
最后的slave机器
- cat id_rsa.pub >> authorized_keys
- scp authorized_keys master:/home/[用户名]/.ssh 传递到下一个slave机器,注意master
然后让master分发密钥
scp authorized_keys slave[n]:/home/[用户名]/.ssh 依次执行
分发流程图
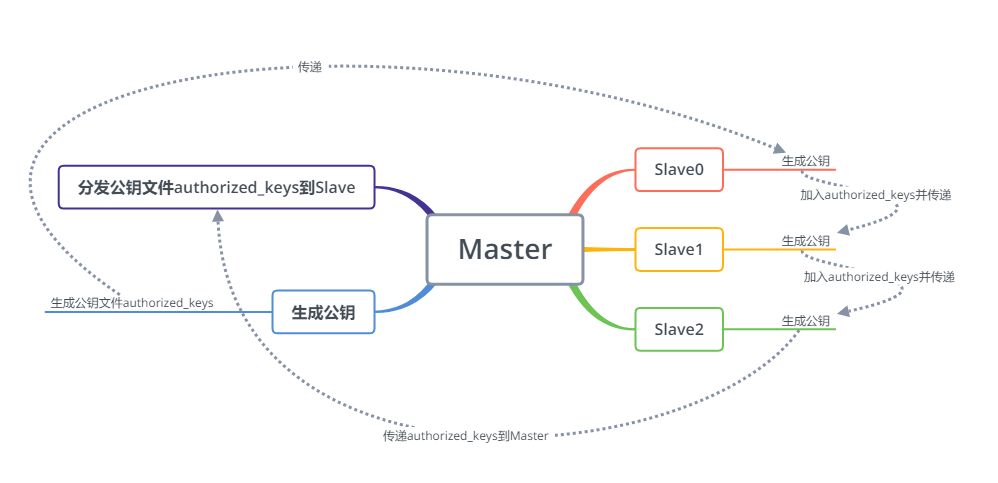
- 注意此时Master可以任意连接slave,slave彼此也能连接,但是不能免密连接master
配置Hadoop
开始配置
- 下载链接 http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
- Hadoop 2.7.7
- 下载安装包解压
- 用winscp等工具上传到centOS
- cd 到自己的用户目录
- tar zxvf hadoopxxxx.tar.gz 解压
完全分布式模式的配置
创建一个tmp目录在Hadoop解压的文件目录下
进入/etc/Hadoop,以下文件操作均在主节点操作
修改core-site.xml
在Configuration内根据自己的实际填入
修改hdfs-site.xml
|
|
修改mapred-site.xml(注意,此文件后缀为.template,删除后缀即可)
|
|
修改yarn-site.xml
|
|
修改masters和slaves文件
- 没则创建,有就直接填入
|
|
主节点向节点复制Hadoo
- scp -r ./hadoop-2.7.7 [slave name]:/home/[username]
格式化完全分布集群(do in master)
- cd /home/hadoop-2.7.7/bin
- ./hdfs namenode -format
启动集群
- cd /home/hadoop-2.7.7/sbin
- ./start-all.sh //会提示废弃,但不用管,能用
使用jsp命令查看节点集群启动情况
web浏览集群
- [IP]:50070 NameNode集群监控
- [IP]:8088 ResourceManager监控
- [IP]:8042 NodeManager监控
系统报告
- cd /home/hadoop-2.7.7/sbin
- ./hdfs dfsadmin -report
坑
Openjdk
- 没有jps,需要在root下执行yum install -y Java-1.8.0-openjdk-devel安装jps插件
Hadoop
- Hadoop 2.7.7 默认没有masters文件,须自行添加使用